Scientific Domain 2:
Computational Biology and Medicine
Life science is a focus research area of the University of Cologne. Data science and simulation are key disciplines in modern biology and medicine. This is also reflected in our activities within the two Clusters of Excellence in this area, one on Cellular Stress Responses in Aging-Associated Diseases (CECAD) and the other one on Plant Sciences (CEPLAS).
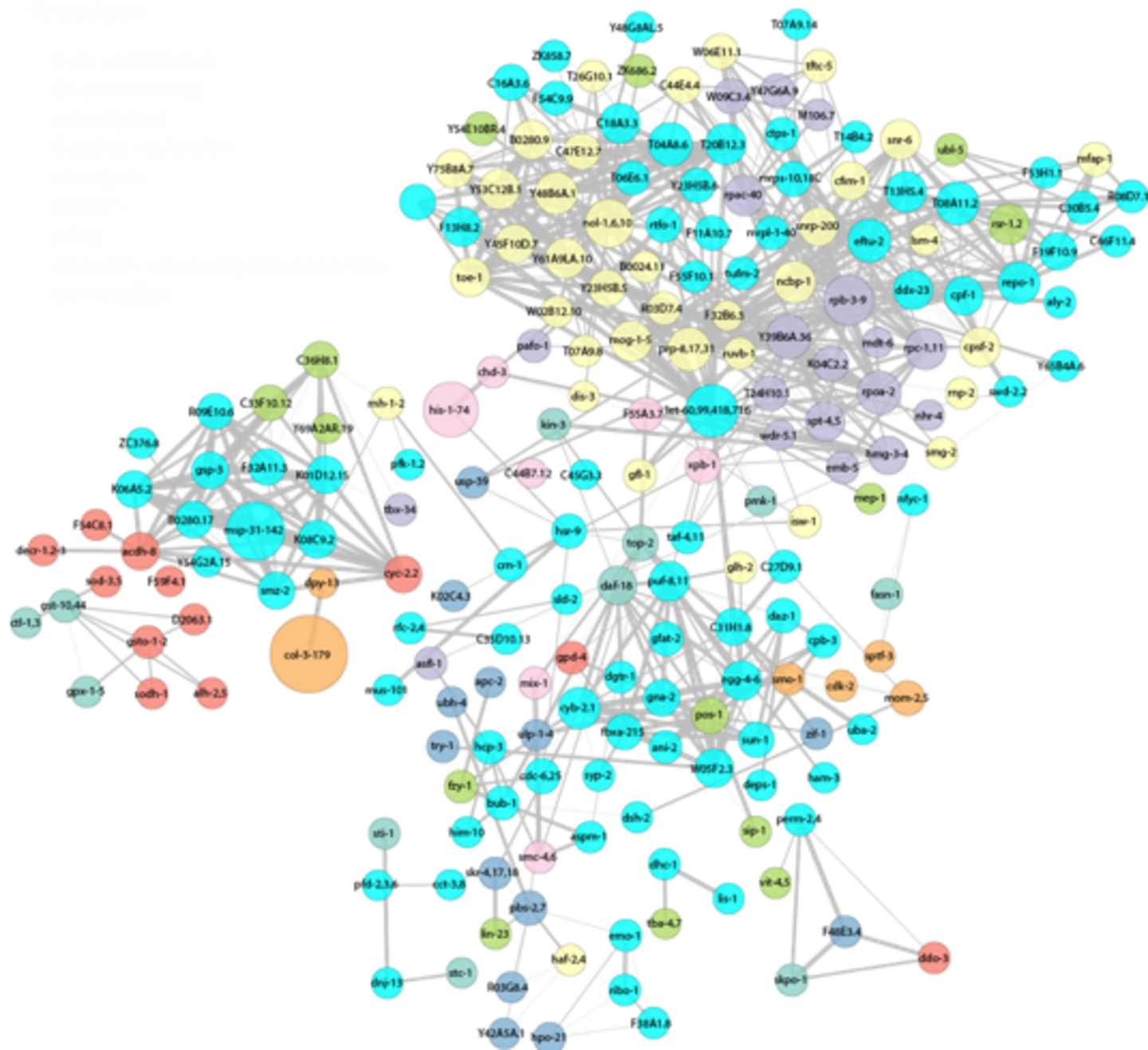
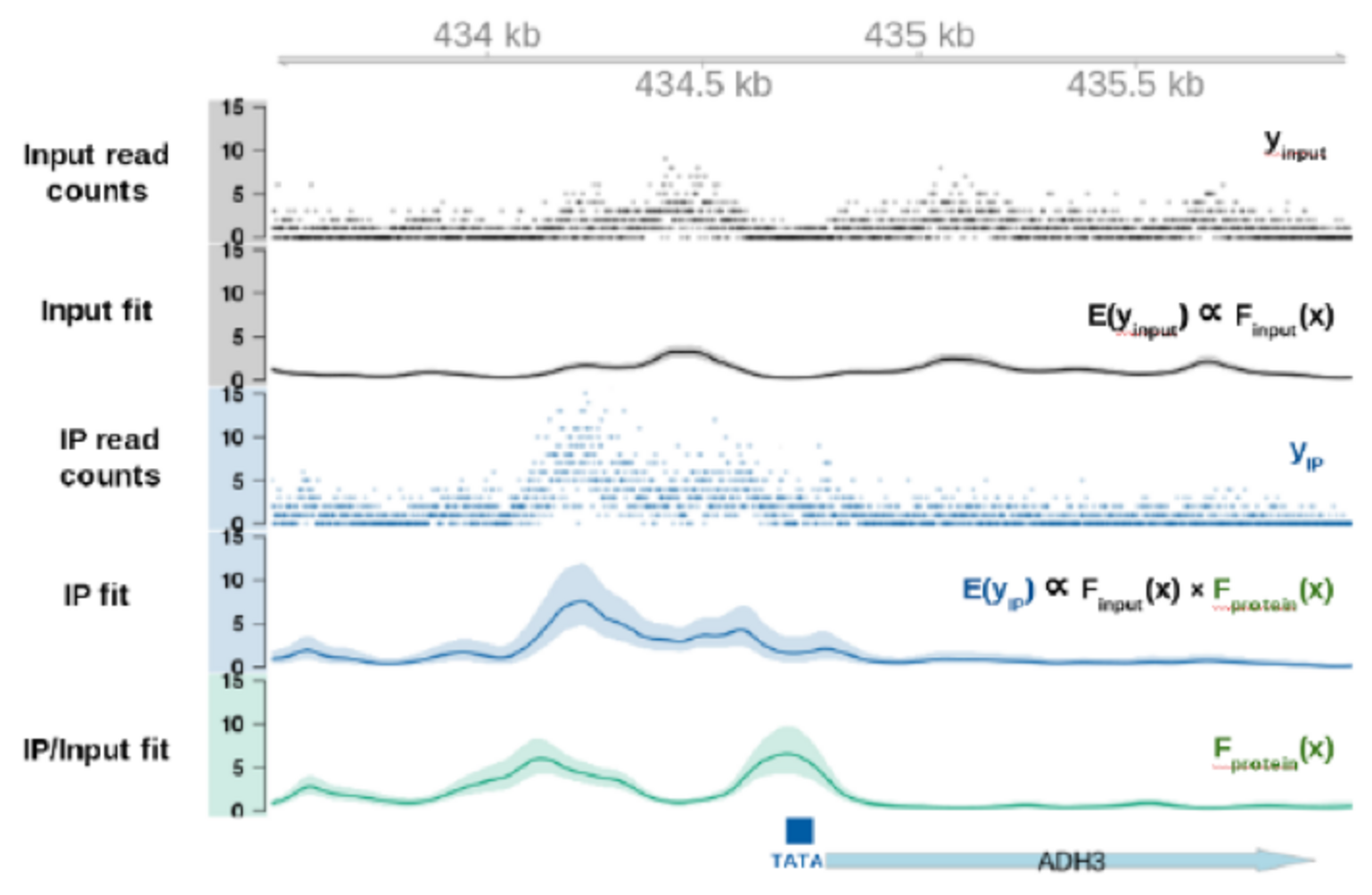
Technologies for DNA-/RNA-sequencing and mass spectrometry have become routine methods, which generate a surge of so-called omics data. The availability of efficient and appropriate computational analysis methods has become key to their understanding. Data is generated at a rate that demands for efficient storage, data compression, and sometimes even online processing. We develop statistical and machine learning methods for the integration and information extraction from multiple omics data sets. One of our major goals is to gain a better understanding of how genotype maps to phenotype in humans by investigating the intermediate layers of biochemical molecules thatpropagate regulatory signals. Ultimately, we improve current strategies to fight genetic disorders or cancer.
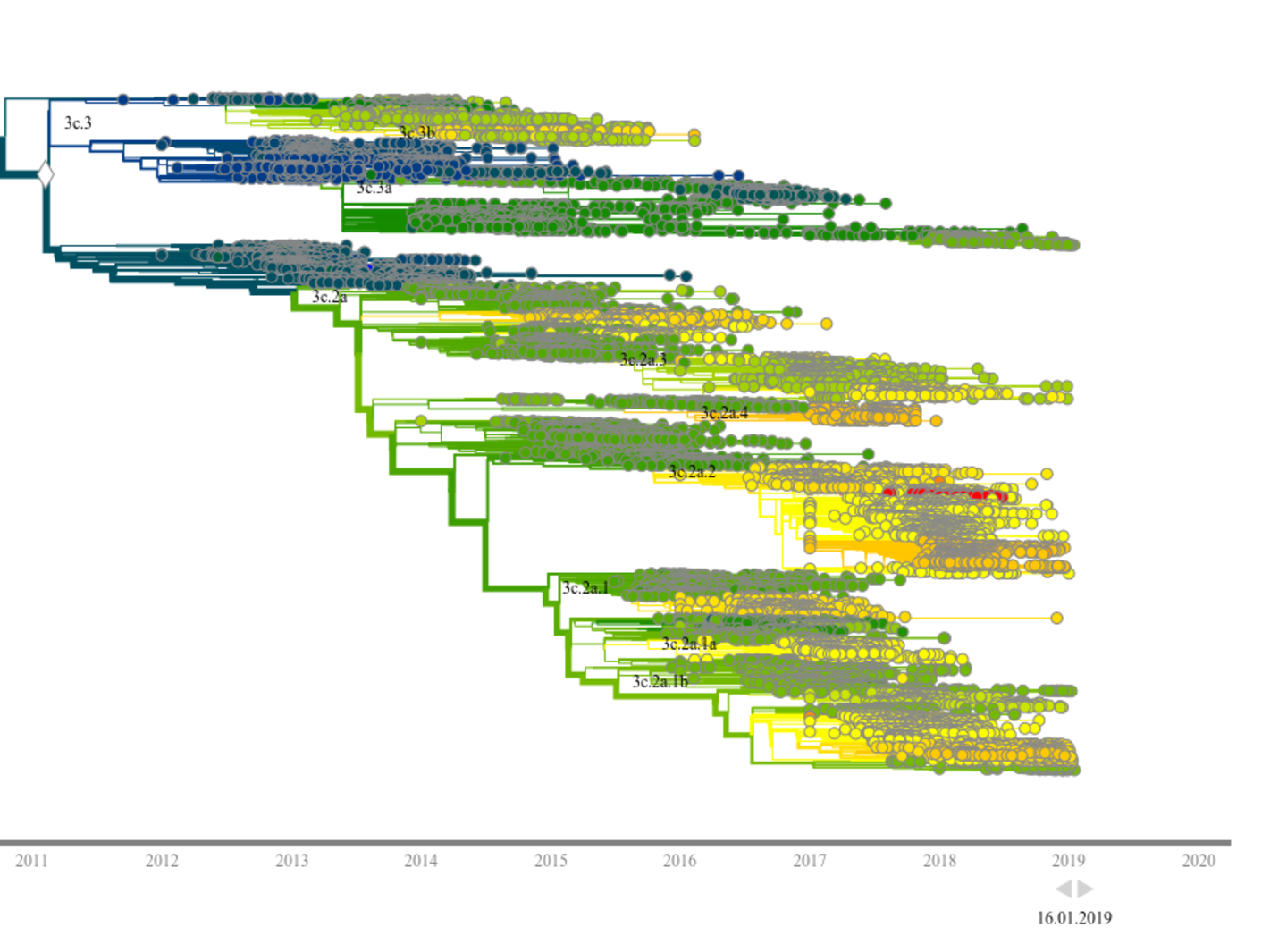
An important focus of life sciences at the University of Cologne is the study of fast evolutionary dynamics, which occur ubiquitously in microbes, viruses, cancer cell populations and immune systems. The analysis of evolutionary processes poses new challenges for data science. These include integrated time-series analysis of sequence and high-throughput molecular data and the inference of dynamical models. We aim to push this inference to predictive analysis, which will lead to new interventions against pathogens and cancer.
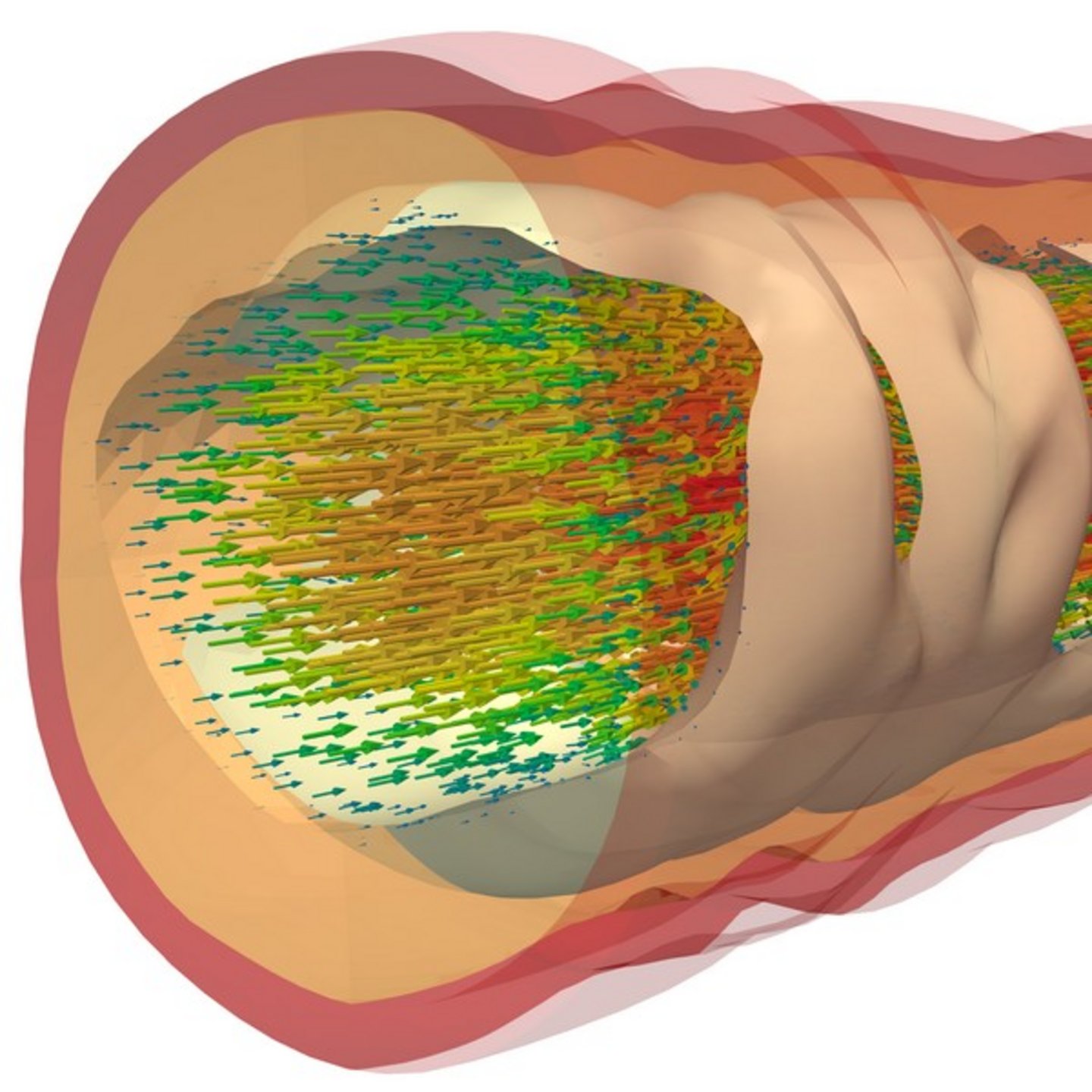
The investigation of cardio-vascular diseases, e.g., arteriosclerosis and arteriogenesis, or brain diseases, can be significantly improved by using numerical simulation techniques. In that way, flow, structural, and also chemical quantities can be simulated which are otherwise difficult to measure in vivo or cannot be experimentally obtained at all. Many of these simulations are also data-driven and require the capability of efficiently using modern supercomputers with tens or even hundreds of thousands of cores. A strong co-design of software and algorithm development is key to master these challenges.
Selected Research Projects